Traditional ETL
Challenges
Why does the industry no longer need traditional ETL/ELT
Business critical decisions, future expansion plans, business investment and divestment decisions, and everything else require complex reports and massive amounts of data. The required data existed in different silos and was not easily accessible, for visualization or analysis, without a whole lot of preparation and generating real-time reports was only a dream.
The complexities in data management quickly led to the evolution of ETL Systems for generating meaningful insights out of Big Data. An ETL system is broad collection of tools that collect data from different sources and load it to data warehouses after transforming it the schema of the target data warehouse.
What enterprises need from their data is straight forward

Connect with any data
Don’t have right connectors, need to right complex custom logic

Shorten time to insights
My reports crawl, I can’t see my data, I need to wait for weeks to run my reports.

Query with Sql
I have no time to learn new technology, can’t find the resource we need, too expensive to hire an expert.

Eliminate data silos
I don’t know where to start, I can’t share my data, I need real-time data, I’m tired of data inconsistency
Challenge traditional way: ETL /ELT process the bottleneck
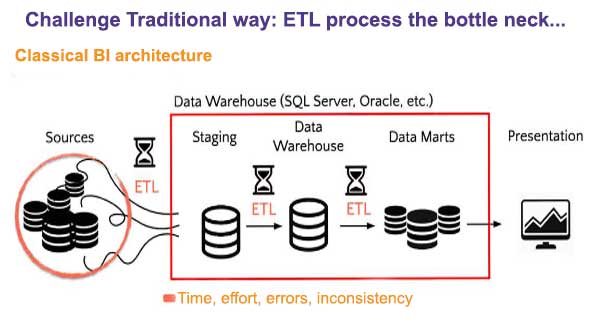
This is a traditional data structure with Data Warehouse and Data marts, each data step involves an ETL Extraction, Transformation and Loading process, this slows down the business intelligence process and makes it complicated and delicate. A change can ruin everything.
Lyftrondata is the fuel of your data success, Try Lyftrondata today for Snowflake migration
More detail challenges of traditional ETL/ELT are define below
Time
Traditional ETL/ELT platforms requires manual efforts and longer time to build the jobs, metadata import for multiple stages like data mart, edw, ods etc.
Errors
Traditional ETL/ELT platforms are very error prone as well, if one stage fails to process so, another stage jobs can’t run which creates the bottlenecks.
Flexibility
Traditional ETL tools copied only certain parts of the data which they deemed to be important resulting in gaps and integrity issues in the data.
Transformation
Legacy tools heavily relied on stringent schemas and failed to handle discrete and unstructured data formats. The lack of the right tools forced analysts to exclude certain parameters from their data models.
Integration
Most legacy systems come with massive hardware requirements and fail to integrate with existing infrastructure resulting in additional overheads for your organization.
Limited processing
Processing capacity of traditional ETL tools is limited only to relational data. They fail to process unstructured and semi-structured data formats resulting data loss and integrity issues.
Efforts
Traditional ETL/ELT platform requires manual efforts to build and manage the data pipeline.
Inconsistence
Traditional ETL/ELT platforms are very inconsistence as well as they don’t provide data replication and schema propagation. So any change from the source needs to be manually ported into the data pipeline.
Scalability
Sudden surge in the data flows are were difficult to manage with traditional ETL tools. The tools failed miserably resulting is long and extremely slow analytical cycles.
Visualization
Gaining a comprehensive view of your data is major challenge with legacy systems. They fail to provide real time access to certain data points resulting obsolete and inaccurate reports.
Cost
Operational, licensing and maintenance costs of traditional ETL tools are very high and add up to the existing costs of the ETL processes.
Lack of vision
Often tools are acquired considering the present data needs of the organization. Traditional ETL tools fail to support future data needs and data formats of the organization.
The evolution of modern data hub & logical data warehouse
The very core of data management is rapidly evolving because the speed and volume of data is growing faster than current technology can keep up with. Traditional methods utilizing obsolete ETL, ELT and building Legacy data warehouses is far too expensive and is overly complicated that requires more time and effort to build the solutions much less support them! As a result we are seeing many companies missing their SLA’s instead of using modern day solutions that don’t have those problems!
90% Faster to implement Higher Performance No ETL/ELT programing is required Modern Cloud Compute Easier Modification Zero Latency
Modern Data Governance & Data Catalog for enterprises
DataCollection is a systematic approach to collect and measure information from a variety of sources to get a complete and accurate picture of an area of interest. Data collection allows an organization answer relevant questions, evaluate results and make predictions about future trends and probabilities.
Correct and systematic collection of data is essential to maintain the integrity of information for decision-making based on data.There is much talk about Data Driven and other similar concepts,but the right approach is talk about “a culture of data.” We may collect thousands of mobile data applications, visiting websites,loyalty programs, and online surveys to meet clients better but for all, we need a system that allows us to manage all these data securely, applying data governance accurate and compliance with laws regulations.
We know that when we talk about Big Data voluminous amounts of structured, semistructured and unstructured data collected by organizations are described. But, because it takes a lot of time and money to load large data into a traditional relational database for analysis, new approaches to collecting and analyzing all this are emerging. We need to collect and then extract large data for information, raw data with extended metadata aggregating this into a Data Lake. From there, automatic learning and artificial intelligence programs will use sophisticated algorithms to search for repeatable patterns.
The problem arises when there is no kind of control and hierarchy when managing these authentic lake data that sometimes grow steadily without really provide value.
Data Collection vs. Entropy
Uncontrolled data collection almost always generate a Data entropy. Sometimes entirely useless data is kept that can only be used once. Have you thought about the large amount of unused data in your systems? Having a control and anti-corruption layer is the only way to prevent Data Entropy.
Logical data warehouse intermediate layer
The LDW technology that resides in Lyftrondata allows a new approach and new flexibility when it comes to managing Data Lake it is even possible to dispense with them due to the capacity of an LDW to contact the source directly in real time and without any intermediaries. Why build a data lake if we can develop and model directly using data sources?
Lyftrondata allows a two-way connection. Data flows directly from different sources to different targets. What Lyftrondata does is transform the data sources into an SQL query. Generating views of all data sources and allowing these sources to be combined, joined, mixed and compared. And that’s not all; we’re going to be able to materialize these views within a Data Warehouse on-premise or in the cloud or even within Apache Spark (which may be the most powerful and economical Data Warehouse in the world even if it wasn’t born for this use).
The integration of new data sources is a lengthy and costly process requiring data modeling, ETL custom development work and complete regression testing.
Traditional data models are often biased rigid questions and are unable to accommodate dynamic and ad-hoc data analysis processes. Unstructured data and semistructured cannot be easily integrated. For this reason, the new technology that drive Lyftrondata has born: The Logical Data Warehouse
Tags good stuff for data collection
Lyftrondata brings you the possibility to have a data classification and to build a data catalog with tags that enables simple data discovery and avoids repeated collection of the same data. Here are some other features that make Lyftrondata the perfect tool for Data Classification:
With Lyftrondata, access to the data collected is instantaneous and real-time. LDW technology eliminates the need to copy and move data. It will be possible optionally if we need to correct the data or link it to other sources. In this way, any customer data can be linked to a customer profile in a CRM.
The characteristics of Lyftrondata allow a data unification in a single format that can be used by any tool. Lyftrondata transforms all data into a SQL Query. You’ll be able to have only Data format anytime without ETL process.
For governance, Lyftrondata provides a single and unified security model with access rights, dynamic row-level security, and data masking, and, most importantly, the GDPR-compliance.
Data collection & self service BI
There has been a lot of controversy among industry experts over the ever-increasing trend of a new approach to BI where business information flows without being overly dependent on IT. Recently, Gartner and Barc researchers emphasised this new approach. Lyftrondata is the best tool for a connection between data collection and analysis without “technical” intermediation. No more job for CTO, because the source data is never touched. A Logical Data Warehouse proposes views and does not copy any data, avoiding tedious ETL processes.
Collecting data with Lyftrondata
If it is true that data collection and classification is the basis of any scientific research, you can imagine how important it can be when analyzing statistical or performance business data. Poor data collection is a poor outcome. If we can connect almost all the existing sources and bring them into our companies’ decision-making processes in real time, the “data-driven” landscape changes significantly.
From abstract concept to solid reality. If we can concentrate all this data in one place without making a copy of it or an ETL process we are giving analysts the possibility to have everything they need to understand what is going on inside organizations. Imagine all data from all data sources available and consolidated without any ETL process. It is the dream that any CTO of any CIO, any manager who wants to transform their organization into a data-driven structure.
Data lake or logical data warehouse?
Lyftrondata is a tool that allows you to create a Data Lake in minutes and the data does not need to be updated because Lyftrondata consults it in real time from the source. If you cannot renounce Data Lake due to its use in machine learning environments, we will be able to use Lyftrondata as an anti-corruption layer of the data lake, providing a controlled intake and Data Governance criteria that are less common in traditional Data Lakes.
We see here the characteristics of Lyftrondata LDW
Provide a logical data warehouse with a columnar high performance data engine.
Emulates engine database most popular and successful on a protocol level (SQL) enterprise-grade, enabling broad adoption and fast without making additional changes to existing tools and infrastructure.
Provides a pure logical data warehouse tool data is fully integrated with Microsoft technology (can be a perfect tool to migrate different sources or other databases to Azure).
- Uses processing engines faster market data such as Apache Spark and others, allowing users easily switch engine and use in parallel,
- Provides a complete self-service portal and administration based on the web.
- Provides internal channeling ETL using parallel column processing.
- Prvides a on-premises deployment model, cloud and hybrid, Allows for easy data governance, Allows the pseudonymisation fulfilling the GDPR standard, Allows for strict control over access to data and solves all safety issues of traditional data lakes.
Benefits of Lyftrondata modern data hub advent of cloud based technologies
Cloud-based technologies have completely transformed the modern enterprise landscape. Enterprises have shifted their focus from long analytical cycles to self-serving applications by adopting cloud technologies. Enterprise level SaaS has gained a wide impetus because of the flexibility and agility it offers over traditional methodologies.
Enterprises can now harness the power of large volumes of data, structured, semi-structured and unstructured, to generate meaningful business insights and focus on adding more value to their customers.
Data explosion
With every passing minute, enterprises are saving petabytes of data in the form of emails, messages, tweets, call logs, IoT and many more. The nature of data from all these sources is highly unstructured and require powerful tools for consolidation and analysis. Legacy systems fail to combine data from all these sources for a holistic view of business and for more data driven decision making.
Real time data for decision support
With the evolution in business processes, enterprises required solutions that are highly flexible and offer them solutions for real-time decision support. The data scenario started changing within minutes and seconds and traditional systems failed to offer the agility required by the modern enterprise.
Cost effective solutions
Storage and maintenance costs turned out to be major concern with legacy systems, however with the advent of cloud data warehouse services like Amazon RedShift and Snowflake these raising costs are no longer a concern. The modern cloud data warehouse services are highly scalable in nature and can automatically scale up or down basing on the surge in the data. They also offer pay as you go services and charge basing on usage.
Access to all data points
One of the biggest advantages of modern data pipe lines is to gain access to all your data points and gain a holistic view of your business. Modern data pipe lines help you to bring all your data together, without any technical limitations, making analysis simple for all stakeholders.
Comparison of some leading ETL/ELT tools
Modern enterprises require solutions that are highly flexible and agile in nature, however the legacy ETL tools failed to address their concerns. Here is a quick comparison of some of the leading ETL tools:
Key Differentiators
Cloud Capabilities
Data Replication
Concurrency
Simplicity
Informatica
Limited support to modern data platforms
- Limited CDC facility
- Limited scalability
- Ingestion of large datasets will have significant impact on the performance.
- Huge learning curve. Requires more time to learn and implement.
Data Stage
Does not support modern data platforms
- No automated error handling or recovery
- Limited scalability
- Huge performance impact while transforming large volumes of unstructured data.
- Difficult to migrate from server to enterprise because of the hugex architectural differences.
Ab Initio
Does not support modern data platformsNo change data capture facilities and must rely on the database for the CDC facility. Limited scalability. Severe performance impact while transforming large data sets and require additional resources for transforming data rich in variety. No automatic scheduling facility. Scheduling must happen manually or through scripts.
Lyftrondata’s value propositions that make it apart from traditional ETL/ELT platforms for Modern data warehouse Migration Time to Insight shorter by 75%
BI users can prototype data sets for analytics on real-time data and replicate the data to Modern data warehouse once the dashboards are finalized.
Iterative migration of a legacy data warehouse to modern cloud data warehouse may be started in 5 days
Lyftrondata Hub works as a pass-through SQL proxy to multiple databases and data sources. Both the legacy DW and Modern data warehouse are connected to Lyftrondata, BI tools are switched to use Lyftrondata as a data source. Lyftrondata accepts SQL queries, translates them and forwards them (pushes down) to the legacy data warehouse or Modern data warehouse. As a result, the data warehouse may be migrated step-by-step. This particular feature is mostly important for migrations from Microsoft SQL Server because Lyftrondata is wire compatible with MSSQL and only the server name must be changed in BI tools from MSSQL to Lyftrondata.
Whole database migration (lyft-and-shift approach) is possible in 10 days, independent of the database size (number of tables)
All data pipelines in Lyftrondata are defined in SQL. This concept enables scripting all data pipelines. This solution is a huge advantage over ETL tools, because data pipelines may be automatically scripted instead of building them manually in a visual designer. A lot of data warehouse architects are looking for a way to apply DevOps principles in the data warehouse design and automate as much as possible via scripting.
Large table scan queries on modern cloud data warehouse may be 1000x faster
When Lyftrondata is used as an SQL proxy that translates SQL queries on the fly. This feature is used when a cube is defined in Lyftrondata. Aggregated queries with GROUP BY and joins are rewritten on the fly to use smaller, preaggregated materialized views. Lyftrondata maintains materialized views for frequently queried combinations of joins and grouping conditions. An example: the main dashboard may always show a graph with the revenue per business unit and such query would have to perform a full table scan for a huge fact table whenever a user opens the main dashboards. With Lyftrondata, it is possible to define a preaggregated view with a GROUP BY bu_id that has only 20 rows. Those queries will execute instantly because they are redirected to a smaller materialized view.
Modern cloud database is usable from ALL BI tools
Lyftrondata works as an SQL proxy (a semantic data layer) between BI tools and Modern data warehouse. Lyftrondata is wire compatible with Microsoft SQL Server and uses Transact-SQL dialect. MSSQL drivers are widely supported by all BI tools on the market. Business users could even connect directly from Microsoft Excel to Modern data warehouse through Lyftrondata, without installing any ODBC drivers, because SQL Server drivers are already preinstalled on Windows.
Windows Active Directory authentication for modern cloud data wareouse possible from any BI tool
Lyftrondata SQL proxy interface is compatible with Microsoft SQL Server and benefits from the heritage of the Windows ecosystem. Lyftrondata may be installed on a computer that is integrated with the customer’s Active Directory domain. Lyftrondata will accept connections from ODBC,JDBC and ADO.NET drivers using Active Directory SSO authentication and translate Windows credentials to effective roles to access Modern data warehouse. As a result, the customer does not need to manage user logins and passwords to enable access to a Modern data warehouse for business users.

Are you unsure about the best option for setting up your data infrastructure?
